
Your large language model worked beautifully in the demo. It answered questions smoothly, handled edge cases gracefully, and impressed every stakeholder in the room. Three months later, it is burning through your API budget at twice the projected rate, your legal team has flagged three hallucinated responses in customer-facing workflows, and your platform engineers are too nervous to push any updates because there is no rollback plan in place.
This is not a rare scenario. It is the default outcome for enterprises deploying LLMs without a structured operational framework. According to Gartner, more than 85% of AI models never reach production. Of the ones that do, a 2025 S&P Global survey found that 42% of companies abandoned their AI initiatives that year, double the abandonment rate from the prior year.
The gap between a working demo and a dependable production system has a name: LLMOps. This guide is a complete operational framework for closing that gap, not just a glossary of tools.
What You Will Walk Away With
|
What Is LLMOps?
LLMOps, or Large Language Model Operations, is the engineering discipline that governs how foundation models are deployed, monitored, evaluated, iterated, and governed in production environments. It extends the principles of MLOps to address a fundamentally different problem set, one that traditional machine learning pipelines were never designed to handle.
With classical ML, the hard challenge was training. You owned the model, you trained it on your data, and your operational job was keeping that training pipeline healthy. With LLMs, you are almost always consuming a pre-trained foundation model, whether GPT-4o, Claude, Llama, or Mistral, via API or self-hosted inference. The hard challenge shifts entirely: what you do with that model’s outputs, how you keep them accurate, how you control cost, how you audit behavior, and how you stay compliant as the regulatory landscape catches up with the technology.
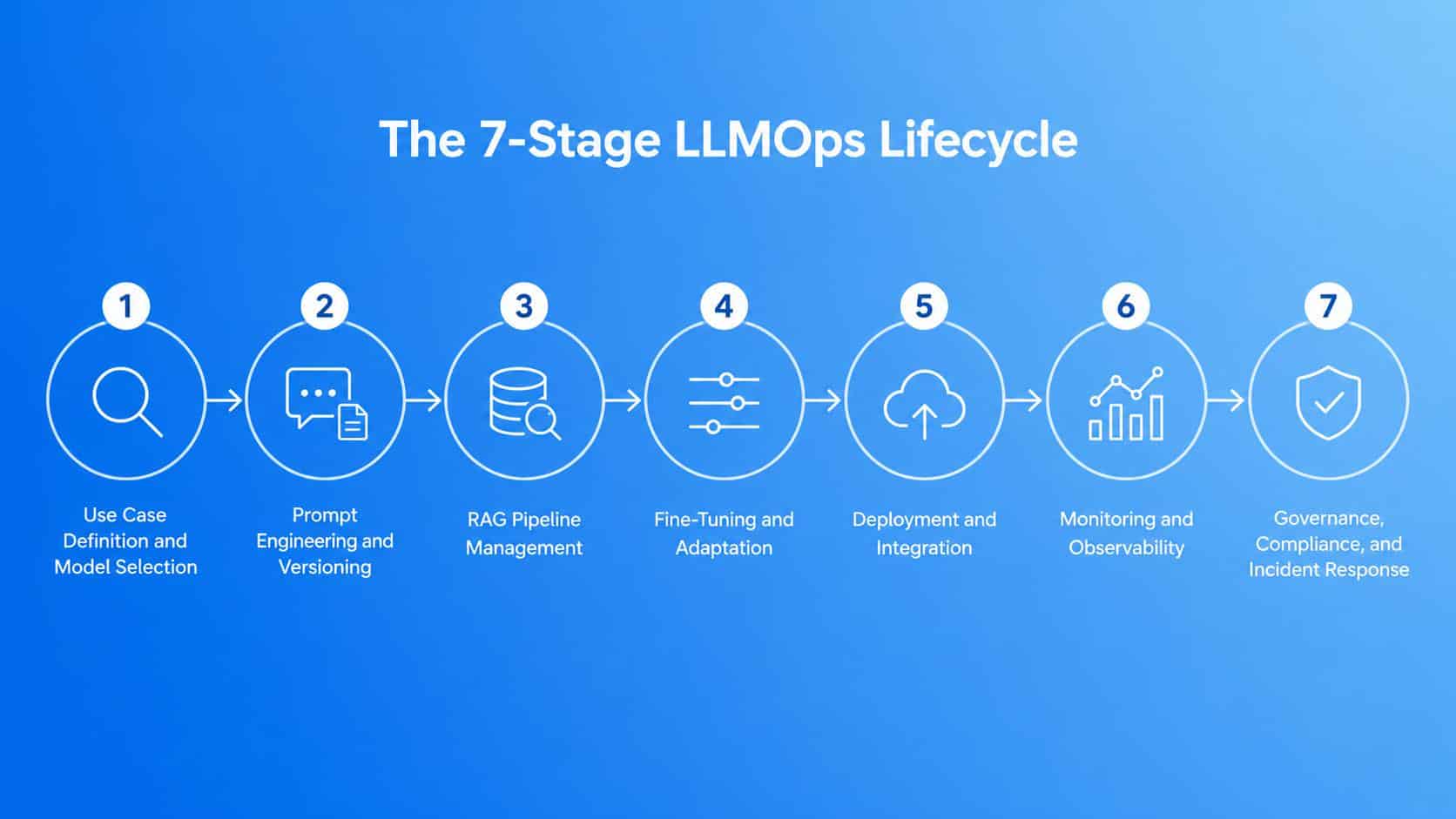
The 7-Stage LLMOps Lifecycle
Unlike a software release, the LLMOps lifecycle does not end at deployment. Model providers update underlying models, user input patterns change, and business requirements evolve. The lifecycle is continuous.
 5")
- Use Case Definition and Model Selection: Choosing the right foundation model for the task, the latency constraints, the compliance environment, and the cost envelope before a single line of code is written.
- Prompt Engineering and Versioning: Designing, testing, A/B testing, and version-controlling prompts as first-class software artifacts with their own CI/CD pipeline.
- RAG Pipeline Management: Grounding model output in live enterprise data through vector search, embedding generation, and retrieval orchestration, then monitoring the health of every layer.
- Fine-Tuning and Adaptation: Updating model weights for behavioral consistency, tone control, and domain-specific precision that prompt engineering alone cannot maintain at scale.
- Deployment and Integration: Serving the model at scale via LLM gateways, APIs, and CI/CD pipelines with automated rollback capability.
- Monitoring and Observability: Tracking latency, token costs, hallucination rates, output drift, and user satisfaction signals in real time.
- Governance, Compliance, and Incident Response: Maintaining audit trails, enforcing access controls, meeting regulatory requirements, and running structured escalation protocols when something goes wrong.
LLMOps vs. MLOps: The Critical Differences
LLMOps does not replace MLOps. Enterprises running both traditional ML workloads and LLM-powered applications need both disciplines. But they address different problems.
| Dimension | Traditional MLOps | LLMOps |
| Primary challenge | Training, retraining, feature engineering | Prompt design, retrieval quality, output governance |
| Model ownership | Custom-trained on proprietary data | Pre-trained foundation model via API or self-hosted |
| Failure modes | Accuracy decay, data drift | Hallucinations, prompt injection, context overflow |
| Evaluation | Accuracy, F1, AUC against test set | Faithfulness, semantic relevance, toxicity, user preference |
| Cost driver | Compute for training runs | Per-token inference costs at production scale |
| Monitoring | Statistical drift on structured outputs | Semantic drift on natural language outputs |
| Iteration cycle | Days to weeks for retraining | Hours for prompt updates, days for fine-tuning |
| Compliance surface | Data governance, model bias | PII in prompts, EU AI Act, prompt injection risk, audit trails |
Why Enterprises Cannot Afford to Skip LLMOps
The business case for LLMOps is not theoretical. It is written in failed projects, ballooning API bills, and regulatory citations.
The Numbers
- $67.4 billion: the estimated global cost of LLM hallucinations in 2024, per OneReach.ai 2025.
- 85%: of AI models never reach production, per Gartner.
- 42%: of companies abandoned AI initiatives in 2024-2025, doubling from 17% the prior year, per S&P Global 2025.
- 30%+: of generative AI projects will be abandoned after POC due to governance gaps and unclear ROI, per Gartner.
- 28%: of organizations have a board-level AI governance strategy, per McKinsey 2025.
- $4.88 million: average enterprise data breach cost in 2024, up 10% YoY, per IBM Cost of a Data Breach Report. LLM prompt injection is now a primary attack vector.
The Cost of Not Having LLMOps
The expenses show up in four categories that typically arrive in this order:
- Token cost spiral. One unmonitored prompt template consuming 80% of API spend despite handling only 20% of traffic. This is not a hypothetical; it is a consistently documented pattern from enterprise LLM observability deployments.
- Hallucination liability. Confident wrong answers in customer-facing or regulated workflows are not occasional bugs. They are production liabilities, and depending on the industry, they carry legal weight.
- Deployment paralysis. Security and compliance teams blocking releases because there is no audit trail, no change approval workflow, and no rollback documentation.
- Pilot purgatory. A working proof of concept that the organization cannot harden to production SLAs because production readiness was never engineered in from day one.
The Regulatory Picture in 2026
Post-2025, governance is not a best practice. It is a compliance requirement.
- The EU AI Act classifies certain LLM-powered applications as high-risk, mandating transparency logs, human oversight mechanisms, and accuracy and robustness documentation before deployment.
- GDPR and CCPA now effectively require PII detection and removal in both LLM inputs and outputs, not just in traditional databases.
- Financial services regulators are moving toward explainability requirements for LLM-assisted decisions in credit, fraud, and trading workflows.
- Healthcare deployments must address HIPAA implications for LLMs that process patient context, including what data enters the prompt and what appears in logged outputs.
Is your LLM initiative stuck in pilot purgatory?
Ailoitte’s AI Velocity Pods embed LLMOps discipline from Day 1.
The 5 Core Pillars of Production LLMOps
Enterprise LLMOps is a system of five interdependent pillars. Weakness in any one propagates to all the others. A team with excellent observability but no prompt versioning will accurately detect problems it cannot trace. A team with rigorous governance but no RAG pipeline management will govern outputs that are confidently grounded in stale data.
 6")
Here is what each pillar requires in production.
Pillar 1: Prompt Engineering and Versioning
Prompts are software. They have bugs, regressions, and breaking changes. The most common reason a well-functioning LLM system degrades in production is a prompt change pushed directly to production because ‘it is just text.’ That assumption is the silent production incident.
- Version control your prompts. Store them in Git or a dedicated prompt registry such as LangSmith or Promptflow, with semantic versioning (major, minor, patch) and mandatory peer review before any change merges.
- Build a regression test suite. A golden evaluation set of 50 to 100 representative inputs and expected outputs is the minimum viable safety net. Every prompt change runs against this set before it ships.
- A/B test in production. Route a percentage of live traffic to the new prompt variant before full rollout. Use shadow mode for high-risk workflows. Define statistical significance thresholds before calling a test complete.
- Govern the system prompt. Define who owns it, who can propose changes, who must approve them, and what the rollback process is. The system prompt is the most privileged piece of code in your LLM stack.
- Harden against prompt injection. Validate and sanitize all user inputs before they reach the model. Build output sanitization to catch injection-induced behavioral changes before they reach users.
In every AI Velocity Pod engagement, Ailoitte treats prompt management identically to application code: pull request review, regression testing against a golden eval set, and a rollback plan documented before any production push. The tooling is secondary. The discipline is the differentiator.
Pillar 2: RAG Pipeline Management
Retrieval-Augmented Generation is the architectural choice that makes LLMs genuinely useful for enterprise knowledge work. Instead of retraining a model to know your internal policies, procedures, and documentation, RAG retrieves the relevant content at inference time and passes it to the model as context.
But RAG introduces its own operational surface area. A stale vector index is one of the most common sources of confidently wrong answers in production LLM systems. The model does not know the document it is citing was superseded six months ago.
- The 3-layer RAG pipeline: ingestion (chunking strategy, embedding model selection, deduplication), retrieval (vector search, re-ranking, permission-aware access), and generation (prompt assembly with retrieved context, output attribution).
- Monitor index freshness. Define a refresh schedule based on how frequently your source documents change. Set alerts when index updates fail or fall behind schedule. Stale indexes are invisible failures.
- Track retrieval quality in production. Context precision and context recall are not just evaluation metrics. Monitor them continuously. A drop in retrieval quality manifests as hallucination before it shows up in user feedback.
- Enforce document lineage. When an output is wrong, you need to know which documents were retrieved, when they were indexed, and who last updated the source. Without lineage, debugging is guesswork.
- Permission-aware retrieval. Enterprise RAG systems must respect the access controls of the underlying documents. A user without clearance to a document should not receive content retrieved from it, regardless of how the query is phrased.
RAG vs. Fine-Tuning: The Quick Decision Rule
- Use RAG when answers must reference live, changing data: product documentation, policy handbooks, knowledge bases, support tickets.
- Use fine-tuning when you need consistent behavioral patterns, output format, or tone that prompt engineering cannot maintain at scale.
- Stack both when you need current facts delivered in a predictable, branded voice. A fine-tuned model for behavioral consistency, RAG for factual grounding. Most mature enterprise stacks use this combination.
Pillar 3: Model Fine-Tuning Strategy
Fine-tuning is the most misapplied tool in the LLM operational toolkit. Teams reach for it to solve knowledge gaps, which is a job for RAG. The correct application is behavioral consistency: when you need the model to follow a specific output format reliably, maintain a consistent brand voice across 100,000 calls per day, or apply domain-specific reasoning patterns that prompt engineering cannot hold stable.
- The economics work. A fine-tuned 7B model replacing a frontier API model at 10 million calls per month typically recovers the full project cost within 30 to 60 days from per-call savings alone. The ROI case is straightforward once the right use case is identified.
- Data preparation is the real cost. Raw GPU compute for a QLoRA run on a 13B model can finish under $100 in 2026. The expensive component is building, cleaning, and labeling the training dataset, plus the evaluation loop. Budget accordingly.
- Parameter-efficient techniques. LoRA and QLoRA are the standard in 2026 for cost-effective fine-tuning on open-weight models. ORPO (Odds Ratio Preference Optimization) is gaining adoption for alignment: it eliminates the separate reference model, cutting memory requirements by 50% and accelerating iteration cycles.
- The anti-pattern to avoid. Fine-tuning a model to remember facts. Models fine-tuned on factual knowledge memorize training examples rather than generalizing, and they hallucinate confidently when facts change. RAG solves the knowledge currency problem architecturally. Fine-tuning solves the behavioral consistency problem.
Pillar 4: Observability and Monitoring
Traditional application performance monitoring tells you whether your LLM is up. It tells you nothing about whether it is right. A system with 99.9% uptime can be silently degrading in output quality for weeks before a business metric catches it.
Enterprise LLMOps monitoring requires five layers working together:
- Infrastructure layer: latency at P50, P95, and P99 percentiles; throughput; error rates; and provider availability. This is the table stakes layer that traditional APM tools cover.
- Cost layer: per-token spend attributed by prompt template, user segment, and use case. Token cost attribution is what turns vague ‘AI costs are high’ conversations into actionable engineering decisions.
- Quality layer: hallucination rate, faithfulness score, relevance, and task completion rate. This layer requires LLM-based evaluation, which is now cost-viable at enterprise scale. Using a capable evaluation model to score production outputs at scale, the LLM-as-Judge pattern, makes systematic quality monitoring practical without prohibitive compute costs.
- Drift layer: prompt drift (how user input patterns shift over time), output drift (where generated content diverges from expected quality or style), and data drift in RAG indexes. Both are invisible without active monitoring.
- User signal layer: explicit signals (thumbs up/down, satisfaction surveys) and implicit signals (conversation completion rate, task abandonment, escalation to human agents). This is the final validation that the system is delivering business value, not just technically functioning.
- Current tooling landscape (2026): Arize AI and LangFuse lead on LLM observability and hallucination alerting; Prometheus and Grafana cover infrastructure metrics; Braintrust is the standard for evaluation CI/CD; Helicone and Portkey for lightweight logging and gateway-level cost tracking.
Pillar 5: Governance and Compliance
Only 28% of organizations have a board-level AI governance strategy (McKinsey, 2025). That is the most underestimated production risk in enterprise AI, because governance failures are not noisy. They accumulate quietly until an audit, a regulatory inquiry, or a customer incident makes them suddenly very loud.
- Data lineage for LLMs. When an output is wrong in production, the team needs to answer: which prompt version ran? Which documents were retrieved? Which pipeline produced those documents? Without this, every debugging session starts from scratch. Stack Overflow’s engineering team described the core insight in April 2026: most LLM issues are fundamentally data issues, caused by missing semantic definitions and undocumented lineage.
- Role-based access control across the pipeline. Who can update prompts in production? Who can trigger model changes? Who has access to logged conversations? These are not IT questions. They are governance questions with legal implications in regulated industries.
- AI Bill of Materials (AI BOM). Document the foundation model version, fine-tuning datasets, retrieval sources, and guardrail configurations for every production system. This is the AI equivalent of a software bill of materials, and regulators in financial services and healthcare are starting to ask for it.
- GDPR, CCPA, and EU AI Act compliance. Post-2025, audit trails for LLM decision chains are a legal obligation in multiple jurisdictions, not a best practice. The EU AI Act specifically requires transparency documentation and human oversight mechanisms for high-risk AI applications.
- Human-in-the-loop escalation thresholds. Define the conditions under which an LLM response triggers mandatory human review before delivery. Build these as hard boundaries, not soft guidelines, particularly in healthcare, financial, and legal workflows.
In every production LLM engagement, Ailoitte establishes the governance layer before deployment. The stack is straightforward. The organizational process (who owns it, who reviews it, who is on call when it fails) is where most enterprises stall. The Ailoitte Engine Room operates with a no-hallucination policy enforced at the code generation layer, .cursorrules firewall governance, and secret scanning integrated into every pre-commit hook. That same discipline carries directly into the LLM systems we build for clients.
The Enterprise LLMOps Architecture
The architecture that supports production LLMOps maps to three layers, each with distinct responsibilities and failure modes.
Layer 1: Model Serving
The LLM gateway sits at the top of the stack. It handles traffic routing across multiple model providers, rate limiting, failover logic, cost allocation, and authorization. Provider-agnostic design at this layer protects against vendor lock-in and enables model routing, using smaller, cheaper models for simpler queries and frontier models only where they add measurable value.
Layer 2: Orchestration
The orchestration layer manages the logic of every inference call: prompt assembly, RAG retrieval, embedding generation, vector database queries, output formatting, and guardrail application. This is where most of the application-specific engineering lives.
Layer 3: Observability and Control
The observability and control layer spans the full stack. It captures traces and logs from every layer, runs evaluation pipelines on production traffic, aggregates cost data, enforces governance controls, and maintains the audit trail. Without this layer, the first two layers are black boxes.
Key Stack Components
| Component | Role in Production |
| LLM Gateway | Traffic routing, rate limiting, provider failover, cost allocation. Supports 250+ models in leading platforms. |
| Vector Database | Persistent storage for embeddings; powers RAG retrieval. Leading options: Pinecone, Qdrant, Weaviate, pgvector. |
| Prompt Registry | Version control and A/B testing for prompts, integrated with CI/CD. Examples: LangSmith, Promptflow. |
| Evaluation Pipeline | Automated quality scoring on every deployment to catch regressions before they reach users. |
| Observability Platform | Real-time tracing, cost dashboards, hallucination alerting. Leading options: Arize AI, LangFuse, Helicone. |
| Guardrails Layer | Input/output filters for PII detection, toxicity, prompt injection, and off-topic content. |
| Model Registry | Version-controlled store of fine-tuned weights, datasets, and training configs. MLflow widely adopted. |
| Fine-Tuning Pipeline | Managed training jobs (LoRA/QLoRA), dataset versioning, checkpointing, eval-gated deployment. |
Build vs. Buy
A Forrester 2025 report found that 76% of organizations now prefer to purchase AI solutions versus build in-house, up from 47% in 2024. That shift reflects hard-won lessons: the hidden costs of building observability, evaluation pipelines, and compliance automation from scratch consistently exceed the cost of commercial platforms.
The practical hybrid that most mature enterprise stacks converge on: buy observability and evaluation tooling; build orchestration logic and domain-specific guardrails; keep the model selection layer provider-agnostic through a gateway abstraction.
6 Critical Production Challenges (and How to Solve Them)
These are not theoretical edge cases. They are the six failure modes that consistently appear in enterprise LLM deployments that lack structured LLMOps practices.
 7")
Challenge 1: Hallucinations
LLM hallucinations cost businesses $67.4 billion in 2024. Confident wrong answers in customer-facing or regulated workflows are not acceptable as occasional bugs. At production scale, they are systemic liabilities.
- Prevention: RAG grounds responses in source documents and keeps them current. Careful prompt engineering can instruct models to acknowledge uncertainty rather than confabulate. Output verification steps can check factual claims before they reach users.
- Detection: Guardrails comparing generated claims against source materials, cross-checking responses for internal consistency, and LLM-as-Judge evaluation patterns that score production outputs for faithfulness at scale.
- Mitigation: UI and response design that surfaces citations, encourages user verification, and routes high-stakes outputs through human review before delivery. Hallucination will never be zero; the mitigation design determines whether an occasional error becomes a scalable liability.
Challenge 2: Model Drift and Prompt Drift
LLMs face two drift types that traditional MLOps never encountered. Prompt drift describes the gradual shift in how users interact with the system, inputs becoming longer, more specific, or structured differently than the model was designed for. Output drift is where generated content diverges from expected quality or style over time.
Both types are invisible without active monitoring. A system can degrade for weeks before a business metric catches it. The fix is straightforward: track the distribution of user inputs, run automated regression tests against a golden eval set on every deployment, and set output quality drift alerts with defined response SLAs.
Challenge 3: Token Cost Explosion
Token costs are not inherently predictable in production, because user behavior is not predictable. Unmonitored enterprise deployments consistently show one or two prompt templates consuming the majority of API spend, despite handling a minority of traffic.
- Token-level attribution: assign costs by prompt template, user segment, and use case. This converts ‘AI costs are high’ into ‘prompt template X is 4x more expensive than expected and can be redesigned.’
- Semantic caching: cache responses to semantically similar queries. For high-volume, repetitive workflows, semantic caching can reduce API calls, and therefore costs, by 30 to 60%.
- Model routing: use smaller, faster, cheaper models for simpler queries. Reserve frontier models for tasks that genuinely benefit from their reasoning capabilities. A routing layer making this decision automatically is one of the highest-ROI investments in an LLMOps stack.
Challenge 4: Prompt Injection and Security
Prompt injection is social engineering for machines. A malicious input feeds the model instructions that override system behavior, extract the system prompt, bypass safety measures, or, in agentic systems, trigger unauthorized tool calls.
In early 2026, researchers demonstrated ZombieAgent-style attacks where indirect prompt injection becomes persistent across connected agent networks, one agent’s compromised output becoming another agent’s malicious instruction. The attack surface expands dramatically with agentic deployments.
- Defense layers: input validation and sanitization before the model sees user content; output filtering before generated content reaches users; sandboxed prompt testing environments; principle of least privilege for tool-calling agents.
- Red-team schedule: treat your production LLM system as an attack surface and test it regularly. Adversarial testing against prompt injection is not a one-time activity. It is a recurring engineering practice.
Challenge 5: The Governance and Context Gap
The emerging consensus from enterprise deployments is captured directly by Citi’s engineering team: “This is not an LLM problem, it is a retrieval problem.” Most hallucinations in customer-facing LLM systems trace back not to model capability but to stale policy documents, conflicting knowledge base entries, and unreviewed draft content feeding the RAG pipeline. A 2026 governance analysis from Atlan documents this clearly: LLM issues are fundamentally data issues caused by missing semantic definitions and undocumented lineage.
The fix is data infrastructure, not model tuning: enforce data lineage from source to vector index, implement document versioning, and build debugging workflows that trace output errors back to specific retrievable root causes.
Challenge 6: Pilot Purgatory
Gartner projects that 30%+ of generative AI projects will be abandoned after proof of concept, not because the technology failed, but because the path from demo to production was never engineered.
The four root causes, consistently: no evaluation framework, no deployment pipeline, no monitoring baseline, and no governance approvals pathway. Each discovered during production hardening rather than before it.
The solution is treating production readiness as a Phase 0 requirement. Define evaluation criteria, deployment pipeline, and governance approvals before any POC begins. The teams that escape pilot purgatory are the ones who build with production constraints from day one, not teams who build the best demo and then try to harden it.
Our Agentic QA Pipeline runs autonomous regression checks on every commit, catching production failures before users do.
LLMOps for Agentic AI: The Next Operational Frontier
Gartner forecasts that 40% of enterprise applications will feature AI agents by 2026, up from under 5% in 2025. Deloitte projects 50% of enterprises using generative AI will deploy agents by 2027. The operational surface area for LLMOps is about to multiply.
Agentic systems introduce failure modes that single-turn LLM monitoring was not designed to catch. In a multi-agent workflow, one agent’s hallucinated output becomes the next agent’s ground truth. An agent that calls external APIs, writes to databases, or triggers workflows does not just produce text. It takes actions. The consequence of a wrong answer is not a bad response. It is a bad transaction.
What AgentOps Adds to the LLMOps Stack
- Tool call logs: every API call, database write, and external action an agent takes must be logged with full context, timestamped, and auditable.
- Action sequencing traces: the full decision chain from initial input to final action, not just the inputs and outputs at each step.
- Loop detection: agents in complex orchestrations can enter infinite retry loops or circular dependency patterns that consume resources without producing outputs.
- Escalation triggers: define conditions under which an autonomous agent pauses and routes to human review. These must be hard boundaries, not soft guidelines.
MCP and A2A Protocol Governance
The Model Context Protocol (MCP) and Agent-to-Agent (A2A) communication standards are expanding the architecture of production agentic systems. Both introduce governance questions that have no LLMOps precedent: which agents can communicate with each other, what data they can share across handoffs, and how authorization is enforced when one agent delegates to another.
Organizations without an AgentOps practice will face compounding operational debt as their agentic deployments grow. The LLMOps infrastructure built for single-model systems is the correct foundation. AgentOps extends it for orchestrated, autonomous systems.
For a deeper look at how Ailoitte approaches agentic system engineering, the Ailoitte Engine Room covers the architecture behind our velocity pod delivery model, including how governed AI code generation and agentic QA pipelines interact.
The Enterprise LLMOps Implementation Roadmap
This roadmap is designed for organizations that have a working LLM application and need a structured path to production-grade operations. Each phase has a clear time horizon, named deliverables, and a definition of done. The phases are sequential by design: Phase 2 assumes Phase 1 is complete.
Phase 1: Foundation (Days 0 to 30)
The goal of Phase 1 is to get observability and a deployment pipeline in place before expanding to additional use cases. Speed here is a trap: teams that skip Phase 1 and rush to scale are the ones who end up in pilot purgatory.
- Deliverables: Model selection rationale documented with cost, latency, and compliance constraints. All prompt templates moved into version control. Basic distributed tracing and logging live across the stack. A golden evaluation dataset of 50 to 100 examples created with expected outputs and edge cases. CI/CD pipeline with tested rollback capability.
- Definition of done: You can deploy a prompt change and detect a regression within 24 hours.
Phase 2: Operationalize (Days 30 to 90)
Phase 2 hardens the system for production traffic. Reliability, cost, and quality monitoring become measurable rather than assumed.
- Deliverables: RAG pipeline live with a documented index refresh schedule and freshness monitoring. Hallucination detection alerts configured with defined response thresholds. Token cost dashboards with attribution by template and use case. Guardrails layer for PII detection and toxicity filtering. Initial governance policy covering prompt ownership, change approval flow, and incident escalation.
- Definition of done: You can identify the root cause of any production quality incident within two hours.
Phase 3: Scale (Days 90 to 180)
Phase 3 optimizes cost, adds fine-tuning for high-volume use cases, and expands the operational model to additional teams and workflows.
- Deliverables: Fine-tuning pipeline operational for identified use cases. Model routing logic based on task complexity. A/B testing framework for ongoing prompt optimization. Compliance audit trail established and reviewed. Multi-team access controls with role-based permissions across the LLMOps stack.
- Definition of done: You can onboard a new LLM use case in under two weeks using the existing infrastructure.
Phase 4: Govern and Evolve (Ongoing)
Phase 4 is not a destination. It is the operational rhythm that keeps the system reliable as the technology, the regulations, and the business requirements all change.
- Deliverables: Board-level AI governance policy covering ownership, risk classification, and review cadence. Quarterly model performance reviews with documented outcomes. Agentic workflow evaluation framework as agent deployments expand. AI BOM for every production system. Red-team schedule on a defined interval.
- Definition of done: Any new regulatory requirement can be assessed for impact and a response plan drafted within 48 hours.
How Ailoitte Operationalizes Production LLMs
Ailoitte is an AI-native product engineering company that has delivered 300+ production systems across 21 countries. The core operational model is AI Velocity Pods, fixed-price, outcome-based engineering pods that combine senior software architects, governed AI development workflows, and agentic QA automation.
LLMOps is not a service Ailoitte sells as an add-on. It is the engineering discipline baked into every pod’s delivery scope. Every engagement ships with a prompt registry, an evaluation baseline, a monitoring dashboard, and a governance runbook. Not because clients ask for it. Because production reliability requires it.
What the Ailoitte LLMOps Practice Covers
- RAG architecture design and vector database selection for complex enterprise data environments, including permission-aware retrieval for regulated industries.
- Fine-tuning pipeline engineering for domain-specific accuracy and cost optimization, with dataset curation and eval-gated deployment as standard deliverables.
- Production monitoring setup with hallucination detection, cost dashboards by use case, and drift alerting integrated into the existing observability stack.
- Governance framework design including prompt ownership policy, change approval workflows, AI BOM documentation, and compliance audit trail configuration.
- Agentic system observability: multi-agent tracing, tool call auditing, and A2A protocol governance as enterprise agent deployments scale.
Industry Applications
- Healthcare AI: HIPAA-compliant LLM deployments with FHIR-integrated RAG pipelines, clinical note processing with hallucination controls, and patient data governance that meets regulatory requirements before deployment.
- Fintech: Explainability-first LLM design for credit and fraud workflows, SOC 2 governance alignment, and audit trail architecture that satisfies both internal risk teams and external regulators.
- Enterprise SaaS: Multi-tenant LLM features with per-tenant cost attribution, guardrail customization by account type, and model routing logic that keeps infrastructure costs predictable as usage scales.
- B2B Platforms: Internal copilots with permission-aware RAG against enterprise data, role-based access controls across the LLMOps pipeline, and fine-tuning pipelines that maintain consistent voice across high-volume workflows.
The outcomes Ailoitte case studies document are not demo outcomes. They are production outcomes: a Tier-1 fintech firm reducing time to MVP from 12 weeks to 5, a 40% cost reduction on an AI-augmented engineering pod engagement, a healthcare platform serving 53 million members with 100% compliance rate. These results come from engineering the operational layer, not from choosing the right model.
Conclusion: The Engineering Discipline Behind Production AI
LLMOps is the difference between a large language model that impresses in a demo and one that creates durable business value at scale. The tools are increasingly mature. The frameworks are documented. The case for investment is written in $67.4 billion of hallucination losses, 42% project abandonment rates, and the coming wave of regulatory enforcement that will distinguish organizations with governance infrastructure from those without it.
All five pillars function as a system: prompt engineering and versioning, RAG pipeline management, fine-tuning strategy, observability and monitoring, and governance. You cannot buy reliability by investing in only one. But you do not need to tackle all five simultaneously. The 4-phase roadmap in this guide is designed to get the foundation right first, then build toward a governed, scalable production practice over 180 days.
The enterprises that invest in this operational discipline now will have a compounding advantage over those that treat LLMOps as a future concern. The technology is no longer the bottleneck. The engineering is.
Ready to ship production AI that stays reliable? Ailoitte’s AI Velocity Pods deliver fixed-price, outcome-based LLM engineering with LLMOps discipline built into every release
FAQs
What is LLMOps?
LLMOps (Large Language Model Operations) is the operational discipline governing how large language models are deployed, monitored, evaluated, and governed in production environments. It extends MLOps principles to address the unique challenges of foundation models: non-deterministic outputs, prompt management, token cost control, hallucination risk, and compliance requirements. Unlike traditional ML systems, LLMs are typically consumed as pre-trained models via API, shifting the operational challenge from training management to output governance.
What is the difference between LLMOps and MLOps?
Traditional MLOps focuses on training pipelines, model retraining, and feature engineering for custom-built models on structured data. LLMOps focuses on prompt management, retrieval orchestration, output quality, and compliance for pre-trained foundation models on unstructured data. The failure modes are different (hallucinations and prompt injection vs. accuracy decay), the evaluation methods are different (semantic scoring vs. statistical metrics), and the cost driver is different (per-token inference vs. compute for training). Both practices can and should coexist in enterprises running both model types.
Why do AI projects fail in production?
The most common failure is not technical. It is operational. Projects that reach production without an evaluation framework, a deployment pipeline, a monitoring baseline, or a governance approvals pathway consistently fail to maintain reliability at scale. Gartner’s research attributes 85% of AI model failures to production deployment challenges, not model capability. The S&P Global 2025 survey found 42% of companies abandoned AI initiatives in the past year, doubling the prior year’s rate, with governance gaps and unclear ROI cited as the leading causes.
What are the best LLMOps tools in 2026?
No single platform covers the full stack. Most enterprise deployments use 3 to 5 specialized tools: LangSmith or Promptflow for prompt tracing and versioning; Arize AI or LangFuse for observability and hallucination alerting; MLflow for model registry; Braintrust for evaluation CI/CD; and an LLM gateway (Portkey, LiteLLM, or a cloud-native option) for traffic routing and cost attribution. The governance and data lineage layer, which most LLMOps platforms do not natively cover, typically requires additional infrastructure around vector database management and document versioning.
When should I use RAG vs. fine-tuning?
Use RAG when answers must reference live, current data: product documentation, internal policies, support tickets, or any knowledge base that changes over time. Use fine-tuning when you need consistent behavioral patterns, output format, or tone that prompt engineering cannot maintain at scale, typically above 100,000 calls per day where prompt token costs make shorter inputs economically important. Most mature enterprise stacks combine both: a fine-tuned model for behavioral consistency, with RAG for factual grounding. The most common mistake is fine-tuning a model to remember facts, which is architecturally fragile and requires expensive retraining every time facts change.
What LLMOps governance is required for EU AI Act compliance?
High-risk AI system classifications under the EU AI Act require transparency documentation, accuracy and robustness validation before deployment, human oversight mechanisms with defined escalation protocols, and audit trails covering the full decision chain. Organizations deploying LLMs in high-risk categories (credit, healthcare, critical infrastructure, employment) need an AI Bill of Materials, data lineage records from source documents through retrieval to generated output, and a change management policy covering prompt updates and model version changes. Verify current enforcement timelines with legal counsel, as implementation schedules have been subject to revision.
How does LLMOps handle hallucinations?
Through a three-layer approach. Prevention focuses on architectural choices: RAG grounds responses in source documents, prompt engineering instructs models to acknowledge uncertainty, and output verification steps check factual claims before delivery. Detection uses LLM-as-Judge evaluation patterns, fact-checking guardrails against knowledge bases, and cross-response consistency checks to identify hallucinations in production traffic at scale. Mitigation limits the damage when hallucinations occur: UI design that surfaces citations, user verification prompts for high-stakes outputs, and human escalation thresholds for regulated workflows. Perfect hallucination prevention remains unsolved; the operational design determines whether occasional errors remain acceptable edge cases or become systemic liabilities.

Discover how Ailoitte AI keeps you ahead of risk

Sunil Kumar
Sunil Kumar is CEO of Ailoitte, an AI-native engineering company building intelligent applications for startups and enterprises. He created the AI Velocity Pods model, delivering production-ready AI products 5× faster than traditional teams. Sunil writes about agentic AI, GenAI strategy, and outcome-based engineering. Connect on
LinkedIn

Stephan is the sports journalist for the Maple Grove Report.